
Apache Kafka’yı çoğumuz duymuştur, kendisini açık kaynak dağıtık bir event streaming platformu olarak tanımlıyor. Bugün Kafka’nın standart message broker özelliklerinden ziyade Kafka Streams’i irdeleyeceğiz.
- Yazı: Kafka Streams Nedir
- Yazı: Kafka Streams KTable
- Yazı: Kafka Streams Stateful Operations
- Yazı: Kafka Streams Windowing
Neden Kafka Streams
Aklınıza şu geliyor olabilir, ben zaten Kafka ile ihtiyacım olan şeyleri gerçekleştiriyorum, niçin streaming dünyasına gireyim ki? Özellikle verinin çok büyüdüğü ve bu veri üzerindeki işlemlerin arttığı bir dünyada artık işlem gücü aynı paralellikte artmıyor. Saniyede yüzbinlerce, milyonlarca sensör verisinin toplandığı bir dünyada bunları işlemek, yönetmek daha da güç hale geliyor. Güzel haber şu ki henüz bir çok uygulamada elimizdeki donanımların gücünü gerçekten maksimize kullanmıyoruz. Bunun için olabildiğince Concurrency’i ve Multithreadleri doğru şekilde kullanan uygulamalar kodlamamız lazım. Bu da uğraşanlarınızın tahmin edeceği üzere bolca race condition ve concurrent update problemleri ile uğraşmak demek. Bunun asıl sebebi de elimizde bolca mutable objenin varlığı ve onları yönetmenin başlı başına bir tecrübe, dikkat işi olması.
Öyle bir kod yazmalıyız ki çok threadli ve çok işlemcili bir mimaride robust bir şekilde çalışabilsin ve bunun için immutabilityi mimarisinin orta noktasına koysun. Immutability mimarimizin merkezine oturduğunda declerative programming bunu implement etmenin belki de en güzel yolu. Bu noktada bir okuma önerisi ile gelebilirim, Robert C. Martin’in Clean Architecture kitabının Functional Programming başlığına bir göz atın.

Kafka Giriş ve Kurulum
Yazı boyunca aynı dili konuşabilmemiz için bazı kavramların üzerinden geçelim.
Kafka’ya paylaşılan veriyi paylaşan tarafa Producer, veriyi tüketen tarafa Consumer ismi verilir. Paylaşılan veri Record, kaydolduğu nokta Log, her Record’a tekil erişimi sağlayan bir Offset sıra numarası ve bu verileri tüketen Consumer’lardan oluşan Consumer Group’ları vardır.
Kavramları ortaklaştırdığımıza göre yavaştan başlayabiliriz. Anlamak için örnekler her zaman daha açıklayıcı, bu sebeple ilk önce demo ortamını kuralım. https://kafka.apache.org/downloads adresinden kafkanın son versiyonunu indirelim ve paketi bilgisayarımızda uygun bir konuma çıkartalım. Benim sürümüm kafka_2.13–3.3.1.tgz sürümü olacak.
Kafka’yı ayağa kaldırmak için https://kafka.apache.org/quickstart adresindeki yönergeleri izleyebilirsiniz. Tercih ettiğim 3.3.1 sürümü ile birlikte consensus problemini çözmek için artık Zookeeper’a ihtiyaç bulunmuyor. Zookeeper’a alternatif olarak pakete dahil gelen KRaft’ın shutdown lar sonrası recovery sürelerinin majör şekilde iyileştirmesi en önemli özelliği. Ben de bugün Kafka’yı KRaft ile ayağa kaldıracağım.

KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
bin/kafka-server-start.sh config/kraft/server.properties
Tek Broker’lı Kafka Cluster’ımız demo için artık hazır. 9092 portundan bootstrap serverımız yayın yaparak oluşturduğumuz cluster hakkında metadata paylaşımında bulunuyor. Bu veri içerisinde topic’ler, onların partition’ları, bu partitionlar için leader brokerlar gibi bilgiler yer alıyor. Bir Spring Boot projesi yaratalım.
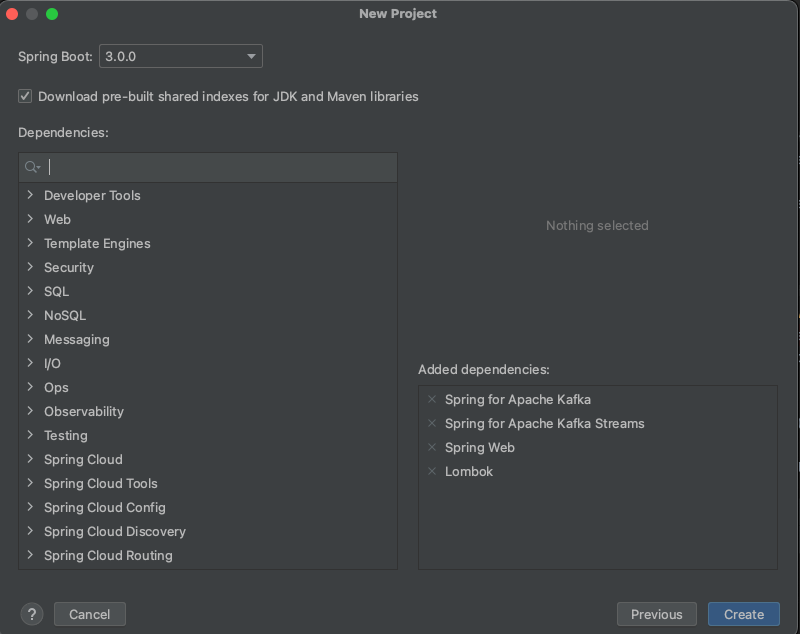
Kafka, Kafka Streams, Web ve Lombok bağımlılıklarımızı ekleyip projemizi yaratıyoruz.
Oluşan projemizin application.properties dosyasına uygulamamız ayağa kalkarken kafka clusterına erişebilmesi için gerekli metadayı edinebileceği bootstrap yapılandırmasını ekliyoruz.
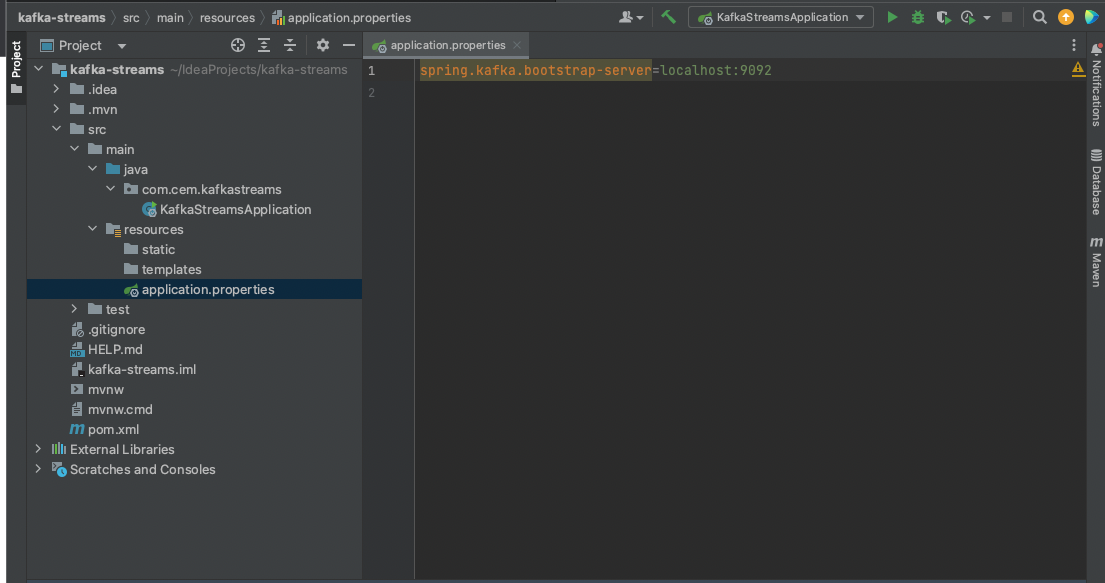
Bu yapılandırma bilgisi ile konfigürasyonumuzu tamamlayalım.
@Configuration
@EnableKafka
@EnableKafkaStreams
public class KafkaConfig {
@Value(value = "${spring.kafka.bootstrap-servers}")
private String bootstrapAddress;
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
KafkaStreamsConfiguration kStreamsConfig() {
Map<String, Object> props = new HashMap<>();
props.put(APPLICATION_ID_CONFIG, "cem-kafka-streams");
props.put(BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
props.put(DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
return new KafkaStreamsConfiguration(props);
}
}
Serdes= Serializer-Deserializer.
Apache Kafka key-value ikilileri ile çalışır. Key ve valuelar transfer edilebilmeleri için serileştirilmeye ihtiyaçları vardır. Projemize eklediğimiz bağımlılıkların içerisindeki Serdes sınıfında bazı hazır serializerlar vardır. Kompleks objeler için Custom Serdes’ler yaratabilirsiniz. JSON, Avro veya Protobuf kullanıyorsanız yine hazır Serdes’ler mevcut.
Kafka Streams
Artık konfigürasyonumuz hazır olduğuna göre önce topiclerimizi yaratalım, sonrasında da basit bir stream pipelineı yaratalım ve temel fonksiyonları tanıyalım.

bin/kafka-topics.sh --create --topic basic-stream-input-topic --bootstrap-server localhost:9092
bin/kafka-topics.sh --create --topic basic-stream-output-topic --bootstrap-server localhost:9092
Declerative programlama ile daha önce uğraşanlar için çok da yabancı olmayan fonksiyonları görüyoruz.
@Component
public class BasicStream {
private static final Serde<String> STRING_SERDE = Serdes.String();
private static final String INPUT_TOPIC = "basic-stream-input-topic";
private static final String OUTPUT_TOPIC = "basic-stream-output-topic";
@Autowired
void buildPipeline(StreamsBuilder streamsBuilder) {
KStream<String, String> messageStream = streamsBuilder.stream(INPUT_TOPIC, Consumed.with(STRING_SERDE, STRING_SERDE));
messageStream .peek((key, val) -> System.out.println("1. Step key: " + key + ", val: " + val))
.mapValues(val -> val.substring(3))
.peek((key, val) -> System.out.println("2. Step key: " + key + ", val: " + val))
.filter((key, value) -> Long.parseLong(value) > 1)
.peek((key, val) -> System.out.println("3. Step key: " + key + ", val: " + val))
.to(OUTPUT_TOPIC, Produced.with(STRING_SERDE, STRING_SERDE));
}
}
İlk peek ile topicten okunan değeri göreceğiz, sonrasında gelen değerin substringini alarak değerimizi mapleyeceğiz, yani dönüştürerek sonraki adıma aktaracağız. En son da filtreleme yaparak parse ettiğimiz değerin 1den büyük olmasını bekleyeceğiz, eğer değilse son adıma bir kayıt geçmeyecek dolayısı ile output topic e bir veri gönderilmeyecek.
Bu akışı yönetebilmek için input topic ine bir producer yaratacağız. Çıktıyı gözlemlemek için de output topic ine bir consumer açacağız.
bin/kafka-console-producer.sh --topic basic-stream-input-topic --bootstrap-server localhost:9092
bin/kafka-console-consumer.sh --topic basic-stream-output-topic --from-beginning --bootstrap-server localhost:9092
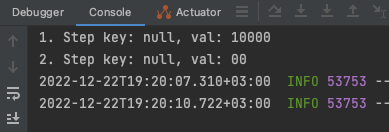
Test etmek için 10002 içerikli bir recordu produce request olarak ilettik.

Bu değer stream olarak ele alındığında aşağıdaki şekilde steplerden geçti.

Son adım olarak da output topic inin içerisinde maplenerek değişmiş haliyle kaydımızı gözlemledik.

Aynı işlemi 10000 recordu için tekrarladığımızda filterdan geçemediği için sonraki adım gerçekleşmemiş oldu.
Bunlar basit bir streaming örneğiydi. Bu girişin ardından sonraki yazımızda asıl faydayı sağlayacağımız KTable konusuna değineceğiz.
- Yazı: Kafka Streams Nedir
- Yazı: Kafka Streams KTable
- Yazı: Kafka Streams Stateful Operations
- Yazı: Kafka Streams Windowing
Projenin kodlarına buradan erişebilirsiniz.